Még a Facebooknak sem egyszerű eldönteni, hogy két ember gyűlöli, vagy szereti egymást az interneten
Moderációs szempontból alighanem az elmúlt évek legfontosabb mozzanata volt az, amikor októberben a Facebook bejelentette, hogy az általuk 2018 óta építgetett, ám tőlük független felügyelőtanács korlátozottan ugyan, de már fogadja a vitás ügyeket. A cég ezzel hatalmasat lépett a transzparencia irányába, a cég azonban idén is számtalan kritikát kapott a megkérdőjelezhető és furcsa tartalomszabályozó döntéseiért, legyen szó akár a koronavírus-járványról, a gyűlöletbeszédről vagy az amerikai elnökválasztásról. A Facebook idén a járvány hatására még a tervezettnél is jobban elkezdte bevonni a munkába a mesterséges intelligenciát és a gépi tanulásos módszereket, ami kétségtelenül képes volt pótolni a távmunkával kieső emberi moderátorokat, ám korántsem volt tökéletes, és egy újabb változót hozott az egyébként is rettenetesen bonyolult egyenletbe.
A Facebook ugyanakkor a jelek szerint eléggé eltökélt abban, hogy ezekkel a technológiákkal hosszú távon jobbá tegyék a közösségi oldalukat, csütörtök délután pedig egy kerekasztal-beszélgetésen engedtek betekintést abba, hogy jelenleg pontosan hogy működik a tartalomszabályozó rendszerük. Az előadás során kiderült, hogy a cég a mesterséges intelligencia segítségével mostanra képes sokkal jobban rangsorolni az irányelvekbe ütköző tartalmakat, ami nemcsak felgyorsítja, hanem javítja is a moderáció folyamatát, és azt is garantálja, hogy az emberi moderátorok többet foglalkozhatnak a komplexebb problémákkal.
Jönnek a gépek
A csütörtöki beszélgetésen a Facebook közösségi integritásért felelős csapatának két szakértője, Chris Palow és Ryan Barnes mutatták be a mesterséges intelligencián alapuló új rendszerről, akik röviden összefoglalva a vitás bejegyzésekről döntő moderátorok mellett azért dolgoznak, hogy a különféle témákban járatos szakértők által alkotott irányelveket tényleg be is tartsák a platformon. Az ő feladatuk az, hogy a minimumra csökkentsék a rossz élményeket a Facebookon úgy, hogy sokszor akár proaktívan fellépnek a káros tartalmak, illetve az azt posztolók ellen is, eközben pedig a lehető legkevesebbet hibáznak. Ez persze elég nehéz, mert naponta több millió döntést kell meghozniuk, köztük sok bonyolult, apró nüanszokkal járó ügyekkel.
A káros tartalmak szűrésénél a prevalenciát akarják csökkenteni, és ezt használják arra, hogy megállapítsák, mennyire elterjedt a káros tartalom. Ez ránézésre tisztán statisztikai módszerekkel zajlik, az előadáson elhangzó példa alapján vesznek egy kisebb, reprezentatív mintát az összes posztból, majd megnézik, hogy ebben hány káros poszt található. Később aztán ez alapján következtetnek az összes posztra, a későbbi mérések eredményeivel összehasonlítva pedig meg tudják állapítani, hogy milyen a prevalencia aránya. A képletben emellett az is számít, hogy hányan látják a posztot, ez ugyanis lehet több millió ember, de akár nulla is.
A Facebooknál kezdetben elsősorban a felhasználók jelentései alapján, főként manuálisan zajlott a moderáció, azóta viszont egyre többet alkalmazzák a káros tartalmakat sokkal hamarabb kiszűrő proaktív moderációt elősegítő eszközöket, így a mesterséges intelligencát is. A technológia fejlődésével, egyre inkább elkezdtek erre támaszkodni, ezzel pedig rengeteg időt takarítanak meg, a spamet például a manuális eltávolítás helyett szinte minden esetben ki tudja szűrni a gép is. Az idei második negyedéves adataik alapján szinte mindent 97-99 százalék körüli arányban képesek proaktívan szűrni, és a gyűlöletbeszéd, valamint a lőfegyvereket tartalmazó posztok esetében is bőven 90 százalék fölött vannak, a zaklatásnál azonban nagy többségében továbbra is a felhasználók jelentései alapján zajlik a moderáció. Ez utóbbira rá is kérdeztünk, külön kitérve a platformról tonnaszámra eltávolított memékre, amire azt a választ kaptuk, hogy az ilyen posztok miatt is rettentően nehéz döntést hozni ebben a kategóriában, mert kontextuális dolgokról van szó.
Palow elmondta, sokszor egy ember is csak a fejét vakarja, hogy egy bejegyzésnél két barát vagy esküdt ellenségek beszélgetnek-e egymással, ezért itt mindenképpen szükségük van arra, hogy valaki elmondja nekik, hogy probléma van egy adott bejegyzéssel. Az új, mesterséges intelligenciára alapuló rendszer pont azért jó, mert lehetővé teszi, hogy az emberi moderátorok többet foglalkozzanak az ilyen esetekkel, de a kontextus megállapítása még így is elég nehéz.
Egy másik kérdésre válaszolva azt is elmondták, hogy a mesterséges intelligencia miatt az olyan közösségekben is tudnak eredményesen moderálni, ahol a csoporttagok alapvetően nem jelentik egymás posztjait, de a csoport fókusza a közösségi alapelvekbe ütközik. A példa itt az önmagukban kárt tevő fiatal lányokra vonatkozott, ami egyébként saját bevallásuk alapján is nehéz ügy, az öngyilkosságot és az önkárosítást ugyanis nagyon óvatosan kell kezelni, nehogy olyasvalaki ellen lépjenek fel, aki segítséget kér a posztjaival.
Új rendszer, jobb eredmények
Az új rendszerben a mesterséges intelligenciát elsősorban arra használják, hogy priorizáljanak a káros bejegyzések között, ezek között ugyanis vannak fontos különbségek, ők pedig elsőként azokkal szeretnének foglalkozni, amiknek azonnali, a való életben érvényes következményei lehetnek. Az is kiderült, hogy sok esetben komplexebb döntésekről van szó, és azt is figyelembe kell venni, hogy akik jelentik a tartalmakat, nem szakértők, így sokszor nincs semmilyen alapja annak, amit csinálnak, vagy akár szándékosan használják rosszul a funkciót. A különböző országokban is nagy eltérések vannak, mind abban, hogy mi jelent problémát, mind abban, hogy mit jelentenek, és mit nem.
A Facebook korábbi modelljével ellentétben a mostani felállásban egységesítve lett a gép által kiszűrt és a felhasználók által jelentett tartalom, amiket a rendszer szűr és több tényező alapján rangsorol, és csak ezt követően jut el a tartalom az emberi moderátorokhoz. A tényezők között szerepel az adott tartalom viralitása, súlya (nagyon súlyos tartalom például a terrorizmus, míg a legalacsonyabb kategóriába tartozik mondjuk a spam), illetve az is, hogy mennyi esélye van annak, hogy szabályokba ütköző a tartalom, mennyiben hasonlít korábban már kiszűrt behegyzésekre.
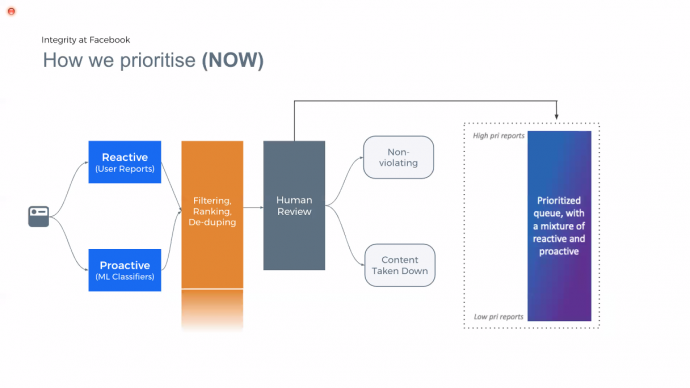
Mint mondták, korábban kronológiai sorrendben haladtak, most azonban a mesterséges intelligencia állít fel rangsort, így a reaktív és proaktív vonalat is ki tudják egyensúlyozni a tényezőknek megfelelően. Ezzel több károsnak ítélt tartalmat ismernek fel, és gyorsabban is tudnak reagálni a jelentésekre. A viralitást gépi tanulással figyelik meg, a gép által alkotott osztályozó plecsnikkel pedig nemcsak azt tudják megmondani, hogy valami sérti-e az irányelveket, hanem azt is, hogy miért. Az egyes kategóriákra specifikusabb címkék is vonatkoznak, amikkel sokkal egzaktabban lehet kiszűrni bizonyos tartalmakat, egyes esetekben pedig a Facebook közösségét is osztályozóként használják, vannak ugyanis olyan ügyek, ahol pontosabban reagálnak a problémára a felhasználói jelentések, mint a saját rendszerük.
Ismét szó esett a Facebook által korábban már bemutatott eszközről, ami egy bejegyzésnél minden tényezőt képes kombinálni egy adott posztból – kép, szöveg, mellékelt link, kép gépi leírása, vagy bármilyen más, kontextusra utaló dolog – és az így kialakított teljes kép alapján egy emberhez hasonlóan képes megállapítani, hogy pontosan miről van szó. Az általuk hozott példában a gép egy drogeladásról szóló posztot ismert fel a kép, az arra írt szöveg, illetve a mellékelt írás segítségével. Hasonlóan fontos az XLM-R nevű nyelveken átívelő, gépi tanulásos megoldás, ami egy nyelven betanítva a koncepciót értelmezve képes más nyelveken is hasonlóan eredményesen működni, így függetlenül attól, hogy milyen nyelvű volt egy szankcionált poszt, hasznos lesz a rendszer számára.
A Facebook szerint az új rendszerrel hamarabb jutnak el a szankciókig, a moderátorok pedig többet dolgozhatnak a komplex döntéseken, így a túlszabályozást és az alulszabályozást is jobban el tudják kerülni. Emellett pedig az új trendeket is időben fel tudják ismerni, így akár előre is felismerhetik, ha valaki káros tartalmakat akar posztolni. A moderátorok egyébként amiatt is jobb helyzetben vannak az új rendszernek köszönhetően, hogy ebben a mesterséges intelligencia képes kiszűrni a leginkább traumatizáló tartalmakat, így lehet, hogy több minden csúszik át hozzájuk, azok azonban nem fogják annyira sokkolni őket. Az persze még így is a távoli jövő, hogy a mesterséges intelligencia önállóan dolgozzon: a beszélgetés alapján a Facebook jelenleg a lehető legtöbb tartalmat szeretné proaktívan eltávolítani, de jelenleg az MI és az emberi moderátorok együtt képesek a lehető legtöbb tartalmat kiszűrni.
