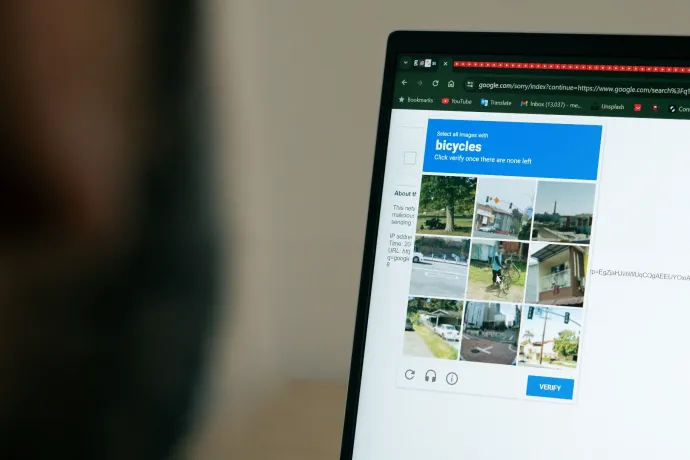
Bizonyára mindenki találkozott már internetezés közben az úgynevezett captchákkal, vagyis azokkal a tesztekkel, ahol ki kell pipálni, hogy nem vagyunk robotok, vagy egy kilenc részre osztott képen meg kell jelölni minden négyzetet, amiben például közlekedési lámpákat látunk. Ezek a tesztek idegesítők, de szükség van rájuk, hogy ne árasszák el a robotok az internetet. Mármint annál is jobban, mint most, amikor az internetes forgalom több mint fele robotokhoz köthető, és azt rebesgetik, hogy az internet halott. Ezeken a teszteken a legtöbben simán átmennek, így felmerül a kérdés, hogy
akkor a robotok miért nem tudják megcsinálni őket, pláne akkor, amikor csak egy üres mezőre kell rákattintani a »Nem vagyok robot« felirat mellett.
A nagyon rövid magyarázat az, hogy azért, mert egy captcha megoldása ennél sokkal összetettebb, pontosabban maga a megoldás igazából a legkevésbé érdekes az egészben. Kicsit hosszabban pedig azért, mert a captchák lényege valójában az, hogy olyan emberi tulajdonságokat keressenek a megoldáshoz vezető út során, amelyeket egy robot nem tud reprodukálni. Legalábbis egyelőre még nem. Ha pedig ennél is bővebb magyarázatot szeretne, akkor olvasson tovább, elmagyarázzuk, hogy működik ez az egész, és miért van nehéz dolguk a robotoknak.
Az első captchát 1997-ben alkották meg, ez volt a régi klasszikus, ahol egy eltorzított, általában értelmetlen szót kellett beírni a szövegmezőbe, hogy bebizonyítsuk, nem vagyunk robotok. A captcha a hivatalos nevét 2003-ban kapta meg, ami igazából CAPTCHA, hiszen egy mozaikszóról van szó: Completely Automated Public Turing test to tell Computers and Humans Apart, vagyis Teljesen automatizált nyilvános Turing-teszt a gépek és emberek közötti különbség megállapítására. Magyarul így hívhatnánk TANYTGEK-nek is, ami sokkal viccesebb lenne, de sajnos nem hívjuk.
Később egy helyett már két szót mutatott a rendszer, amivel nem idegesíteni akartak mindenkit, hanem az első captchák mögött álló, a Google által felvásárolt reCAPTCHA Inc. ezzel is tréningelte azokat az optikai karakterfelismerő rendszereket (OCR), amelyek kicselezésére a captchák létrejöttek. A lényege, hogy az egyik szót (vagy kifejezést) ismeri a rendszer, a másikat viszont nem – ha a felhasználó az ismertet helyesen írta be, akkor a másik szót is helyesnek jelölte meg a rendszer, és más felhasználóknak is feldobta ugyanezt a képet, hogy validálja az eredményt.
Ez a típusú captcha amúgy nemcsak azért volt jó, mert segíteni lehetett vele a Google-nek a modelljei tanításában, hanem azért is, mert miután a 4chan fórumon bevezették a reCAPTCHA-t, külön internetes művészeti ág lett a CAPTCHArt, ahol a random egymás mellé dobált szavakból mindenféle vicces képeket gyártottak, és még rage comicos verziója is lett Lord Inglippel a 2010-es évek elején.
A robotokra visszatérve, azt már igazából le is lőttük, hogy miért nem tudták megoldani ezeket a captchákat: azért, mert az OCR sokáig nem volt erre alkalmas. 2014-re viszont már jobbak is voltak a robotok ebben, és itt jön képbe a következő állomás, az egy évvel korábban bevezetett, pipálós reCAPTCHA v2, ahol az embernek nem volt más dolga, mint belekattintani egy négyzetbe.
Ezt a feladatot tényleg akárki képes abszolválni, a robotoknak viszont fel lett adva a lecke, mert a lényeg nem a pipálás, hanem a felhasználó viselkedésének elemzése volt. Egy captcha klikkelésére betanított robot a lehető leghatékonyabban fogja mozgatni a kurzort, és hiába programozzák úgy, hogy tegyen kitérőket, vagy várjon egy kicsit, még mindig messze van attól, hogy emberi viselkedést produkáljon.
És persze az is fontos, hogy a captcha valójában az égvilágon minden infót lekér rólunk az IP-címünktől a sütijeinken és a böngészési előzményeinken át a kattintásszámunkig, szóval így már tényleg elég nagy magabiztossággal tudja összerakni, hogy emberek vagyunk-e, vagy sem.
A második verzióban jöttek be az olyan képek is, ahol közlekedési táblákat meg motorokat kell keresni, részben azért, hogy a mobilos felhasználóknak egy fokkal könnyebb dolguk legyen. A lényeg viszont itt sem az, hogy hibátlanul nyomjunk rá minden négyzetre, amibe három pixelnyire átlóg a tűzoltóautó visszapillantójának a széle, a helyes megoldást az is befolyásolja, hogy a legtöbb felhasználó mire kattintott. Mark Zuckerberg amúgy két éve egy ilyen teszttel bizonyította, hogy nem robot, bár azóta kiderült, hogy a visszatérő vád ellen az is segít, ha emberien viselkedik.
A képazonosítgatós captchák sokáig kemény diónak bizonyultak, mert rengeteg változóval kellett számolni – például a tükröződés, a fényviszonyok vagy az absztraktabb formák, mint, mondjuk, egy felhő. A mesterséges intelligencia (MI) rohamos fejlődése viszont ebben is változást hozott, egy néhány napja megjelent tanulmányban bemutatták a nyílt forráskódú YOLO (You Only Look Once) finomhangolt változatát, amely egy VPN-nel (amely elrejti, hogy valójában honnan működik), bekamuzott egérmozgással és valódi munkamenetekből kölcsönvett böngészési és sütiinformációkkal megtámogatva 100 százalékában képes volt megoldani az ilyen captchákat.
A Google viszont már évekkel ezelőtt felkészült erre, 2017 óta ugyanis elérhető a reCAPTCHA v3, amely a háttérben meghúzódva teszi a dolgát.
Ehhez már nem kell semmilyen tesztet megcsinálni, hacsak nem jelöl meg gyanúsnak a rendszer. Az azóta is fejlesztés alatt álló rendszert a bevezetése után több kritika is érte, felmerült, hogy megbízhatóbbnak bélyegzi azt, aki be van jelentkezve a Google-fiókjába, és arról is volt szó, hogy mivel a kódot egy adott honlap összes aloldalába be kell építeni, a Google még az addiginál is több infót tud gyűjteni rólunk. A botok ellen viszont még mindig hasznos a rendszer, de az a tanulmány szerzői szerint is biztos, hogy az MI fejlődésével egyre nehezebb olyan captchát találni, amin a legokosabb robot már fennakad, a legbutább ember viszont még nem.
(Források: Cloudflare, KickassFacts)

