Hamarosan nálunk is elérhető lesz a Meta AI. De mi az a Meta AI?
Bizonyára olvasóink közül is sokan találkoztak az elmúlt napokban a Facebookon egy arról szóló értesítéssel, hogy a Meta június 26-ával nálunk is bevezeti az egyre több országban elérhető mesterséges intelligenciás (MI) funkcióit. Az üzenetben a cég arról is tájékoztatott, hogy hogyan használja fel ehhez a felhasználói adatokat. Erről bővebben ide kattintva lehet olvasni, de érdemes azt is összeszedni, hogy pontosan milyen mesterséges intelligenciás funkciókról beszélünk, mert tavaly szeptember óta a Meta is teljes gőzzel próbálja meglovagolni az MI-hullámot.
Mark Zuckerberg cége a tavaly őszi Meta Connecten érthető módon ejtette a szebb napokat is megélt metaverzumot, cserébe viszont előállt a ChatGPT-hez kísértetiesen hasonlító MI-asszisztensével. A nagyon kreatívan csak Meta AI néven futó csetbottal természetesen nem találták fel újra a spanyolviaszt, az igazán érdekes része az volt az egésznek, hogy ez a saját modelljükön, a nyílt forráskódú Llama 2-n alapult. Illetve később az is, hogy mivel nem a Google vagy a Microsoft áll mögötte, a Bing és a Google keresési eredményeiből egyaránt képes dolgozni.
Ehhez persze már az kellett, hogy a Facebook idén április közepén bejelentse a Llama következő generációját, a Llama 3-at, ezzel párhuzamosan pedig azt is, hogy a modelljét beépíti a Messengerbe, a Facebookba, az Instagramba és a WhatsAppba is, és különálló szolgáltatásként is elérhetővé teszi. Mark Zuckerberg akkor azt mondta, azt szeretnék, hogy a Meta AI a legfejlettebb MI-asszisztens legyen, amit szerte a világon bárki használhat, a Llama 3-mal pedig úgy érezte, hogy meg is érkeztek ide.
A Llama 3-ból két modell jelent meg áprilisban, az egyik 8 milliárd, a másik 70 milliárd paraméterrel – ezek lényegében azt határozzák meg, hogy mennyire összetett egy modell, és mennyire jól tud tanulni –, de már akkor bejelentették, hogy érkeznek nagyobbak is, amelyekben a paraméterek száma a 400 milliárdot is meghaladja. Összehasonlításképpen, a tavaly nyáron megjelent Llama 2-ben a legnagyobb modell volt 70 milliárd paraméteres. A tanításhoz használt adathalmaz most hétszer akkora, 2 billió helyett pedig 15 billió token (ezek általában szavak) szerepelt benne.
Ezeket – állítólag – mind nyilvános forrásból, legálisan szerezték be, de azt az előző verzióhoz hasonlóan itt sem osztották meg, hogy pontosan mit használtak hozzá.
Az mindenesetre biztos, hogy az adathalmaz több mint 5 százaléka „magas minőségű, nem angol nyelvű forrás” volt, ami több mint 30 nyelvet fed le, és ez a más nyelvű használatot lenne hivatott gördülékenyebbé tenni. Tavaly a Llamát is érintette a Books3 nevű adathalmaz, amelyben majdnem 200 ezer könyv kalózverzióját lehet megtalálni, és az olyan nemzetközileg ismert szerzőkön túl, mint Stephen King vagy Jane Austen, benne vannak Krasznahorkai László, Nádas Péter és Kertész Imre művei is. Azt nem tudni, hogy ezt a Llama 3-hoz is használták-e.
A Meta a bejelentésében hangsúlyozta, hogy a Llama 3 számos ponton tudott javulni, egyebek mellett például abban is, hogy nem utasít el olyan kéréseket, amelyekben bevett szófordulatok szerepelnek, külön-külön viszont a szavaknak olyan jelentésük van, ami rizikósnak tűnhet. Zuckerberg a Verge-nek itt azt a példát hozta fel, hogy most már lehet vele „killer margaritát” csináltatni – ami természetesen nem megöl valakit, hanem egy nagyon jól sikerült margarita koktél. A Meta szerint a Llama 3 összességében jobban irányítható lett, a saját tesztjeik alapján az összes többi, akkor elérhető modellt kenterbe verte:
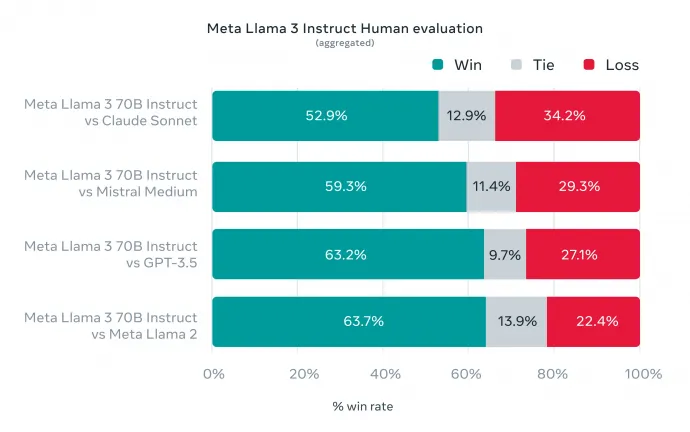
Az tehát jól látszik, hogy a Meta annak ellenére, hogy látszólag kullog a versenytársai után, már eléggé ott lohol a nyakukban, azt viszont azért érdemes hozzátenni, hogy a Llama 3 bejelentése óta a konkurensek sem ültek karba tett kézzel. Május közepén egy nap eltéréssel jelentette be lényegében ugyanazt az OpenAI és a Google is – előbbi a GPT-4o-val, utóbbi a Geminivel mutatta meg, hogy a jövő megérkezett. Ezek a modellek még az elődeikhez képest is hatalmas ugrásnak tűntek, és az eddigi összehasonlítások alapján ezekhez képest azért már nem annyira acélos a Llama 3. Igaz, annak még nincs is kint a piacon a legerősebb változata.
De mit jelent az, hogy a Meta AI nálunk is elérhető lesz? Hát, igazából annyit, hogy a jelek szerint június végén hozzánk is befut az egész, egyelőre még nem használható asszisztens, vagyis különálló alkalmazásként és a Meta szolgáltatásaiba beépítve is használhatjuk majd a mesterséges intelligenciát. Meg fog jelenni a keresőkben, illetve a facebookos hírfolyamunkban, sőt, az összes Messengeres beszélgetésünkben is. A gyakorlatban ez azt jelenti, hogy például
- meg lehet majd kérni, hogy javasoljon helyszínt mondjuk egy randihoz, és küldi is a választ, amit mindkét fél látni fog;
- ha görgetünk a hírfolyamunkban, kérhetünk extra infókat egy posztról – például ha egy gitáros videót nézünk, megkérdezhetjük, hogy lehet dzsesszes akkordokat tanulni, ha meg az északi fényről látunk képet, megmondhatja, mikor van a legnagyobb esélyünk látni;
- és generáltathatunk vele képeket, sőt, létező képekből még animált gifeket is.
Na, és mit jelent az, hogy az adatainkat is fel fogják ehhez használni a jogos érdekre hivatkozva? A frissített adatvédelmi szabályzat alapján azt, hogy az általunk közzétett tartalmakat, üzeneteket (illetve azok egyéb nyilvános adatait) és az általunk használt alkalmazásokat, illetve az abbéli tevékenységeinket felhasználhatják a saját MI-alapú technológiáik fejlesztéséhez és javításához. A Meta hangsúlyozza, hogy a privát üzeneteket nem használják fel a modelljeik tanításához, ezen túl viszont nem igazán derül ki, hogy pontosan mit csinálnak a begyűjtött adatokkal. Ha valaki szeretne tiltakozni az adatgyűjtés ellen, ide kattintva megteheti.
